Databricks Workspace Computing
Author: Christopher Lundy
Creation Date: Mar 9, 2023
Next Modified Date: Mar 9, 2024
A. Introduction
March 9, 2023
Introduction
The Databricks Platform combines the best elements of Apache Spark Compute engines, unified data management, data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes.
This unified approach simplifies Seagen’s modern data stack by eliminating the data silos that traditionally separate and complicate data engineering, analytics, BI, data science and machine learning. It’s built on open source and open standards to maximize flexibility. And, its common approach to data management, security and governance helps us operate more efficiently and innovate faster.
B. How is it used at Seagen
There are several workspaces in use today. Each workspace is comprised of,
compute clusters
workspaces
Identity Management Access with Remote Based Access Controls
connectivity to data sets, stores, lakes, etc.
The current process to create a new workspace includes a team requesting that a new workspace be created in Azure or GCP. If Azure, a GitHub Repository is necessary and should use not only the Databricks Terraform Module but likely the Data Lake modules as well. When it is deployed, it is deployed to a subscription in Azure, into a resource group within that subscription and is logically and physically separated by 3 various environments that conform to the SDLC.
If the cluster is needed in GCP, there is an existing compute cluster already that can be used. Each team member will have their own notebooks. Notebooks are the tools engineers and developers use to write their code and run their code on the Databricks platform.
Packages and Libraries
All packages and libraries are deployed through the Terraform modules. Though the ability to deploy packages and libraries exists within Databricks and can be done manually, Seagen does not allow manual addition or assignment of packages within the clusters. This is done via automation. Databricks, as a platform, has production releases of certain packages, like R or PySpark, and they use their SDLC process to ensure that package is functional across the current production distribution of Databricks. This means that everyone using Databricks, uses the same version(s) of that package. When doing so, Databricks offers support for its use and if issues arise, those issues are remediated by the Databricks support team.
Seagen can also add packages, and does, that are not part of the standardized offering. This is because the Databricks platform is built on an architecture that is composable and extensible. That means that Seagen can add packages as is necessary but the support of those packages is up to Seagen to support. That means if there are issues, Seagen support or engineers need to resolve the issue which may mean moving to a supported version. This may happen when a developer or engineer uses a very old version of a package and that package needs to be reinstalled and cannot be upgraded.
This is not a problem because developers and engineers perform this exercise today. They install and manage their packages locally or on their sandbox or development environment. The only difference is that they need to include that package or library in the automation script.
The key to using packages is to understand the features they offer. That means the Seagen team using those packages needs to understand that package and how it works. Many times, these packages are open source and free to use based on licensing from universities, public domain, or open source. These types of packages or libraries often have a GitHub repository and/or descriptive site that explains dependencies, other software needed, and the prerequisites or conditions of use. That information is the responsibility of the application team to manage when those packages are added and exceed what is offered by Databricks.
Seagen Support
If packages or libraries are added that are not part of the base platform, as mentioned can happen anytime, then the application team using those packages is responsible for the maintenance, support, and documentation necessary to qualify or validate that environment if that application is GxP related. They are also responsible to test that package. It is in Seagen’s best interest to use the pre-packaged libraries or packages thus relying on Databrick’s support.
C. Features
Databricks functions as a Software-as-a-Service running in Azure. Though Databricks creates virtualized environments in Azure, they do so using the Azure Product Development approach. This approach is for 3rd parties desiring to host and operate their application or service on Azure without the overhead of individual deployments. However, an organization can deploy Databricks in their own virtualized or containerized environments that they manage and maintain but doing so removes any value add and requires staff and a detailed understanding of the Databricks ecosystem.
Databricks consists of several features. The features are as follows.
Unified Analytics: Databricks provides a unified platform for data engineering, data science, and business analytics, making it easier for teams to work together and share insights.
Scalable Data Processing: Databricks on Azure provides a scalable data processing engine that can handle large volumes of data, enabling users to build and run data pipelines, batch processing jobs, and real-time streaming applications.
AI and Machine Learning: Databricks on Azure provides a comprehensive set of tools for data scientists to build and deploy machine learning models, including support for popular libraries like TensorFlow, Keras, and PyTorch.
Collaboration: Databricks on Azure provides a collaborative workspace that enables teams to share code, notebooks, and data, making it easier to work together on projects.
Security and Compliance: Databricks on Azure provides enterprise-grade security and compliance features, including data encryption, access controls, and compliance with regulations like GDPR, HIPAA, and SOC 2.
Integration with Azure Services: Databricks on Azure integrates with other Microsoft Azure services, including Azure Storage, Azure SQL Database, and Azure Event Hubs, making it easy to build end-to-end data solutions on the Azure platform.
D. Where implemented
E. How is it tested
Security is established in 3 ways.
Access controls
Security in depth
Authorization
Access Controls
Access is controlled using Azure Active Directory and an integrated connection to the Databricks ecosystem. Users are granted access to the workspace via AAD controls and group based access controls. This is accomplished by assigning individuals or groups to the Terraform files for the Databricks deployment.
Access Controls also exist between Databricks and GitHub Enterprise. When connecting to the GitHub repository, a token is used from GitHub and is stored in the Databricks secure vault.
Security In Depth
Security in depth describes the application of Zero Trust Architecture (ZTA). ZTA describes the separation and microsegmentation of resources and people or groups. As seen from the image below, Databricks is configured with multiple layers of access controls, network segmentation, and auditing. By default, Databricks uses the default security setup provided on the Azure platform.
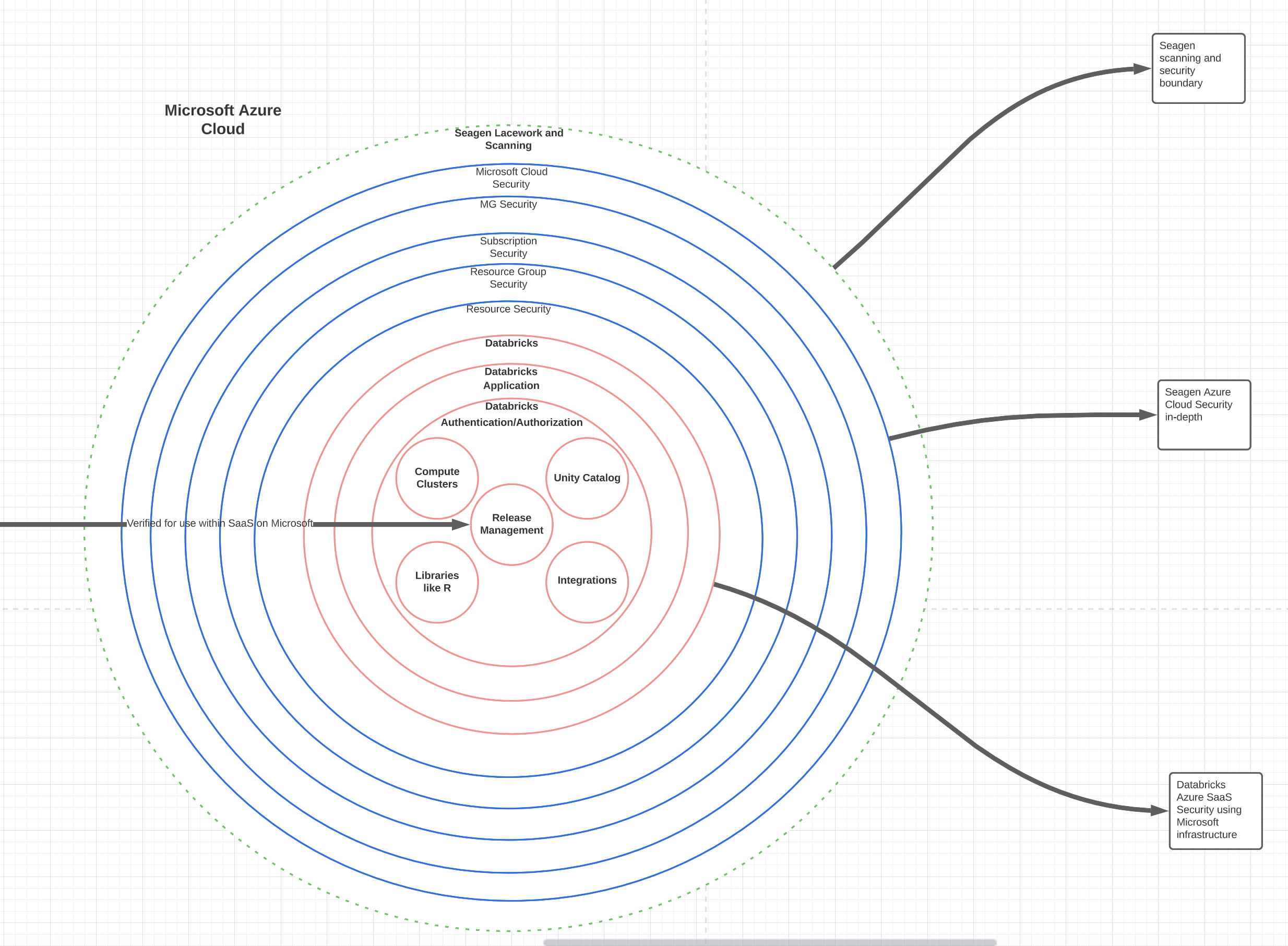
As seen from this model, each ring represents another layer of security and access control. The dotted line on the outside is the testing Seagen does to verify security.
The red circles are in the purview of the Databricks security and access control.
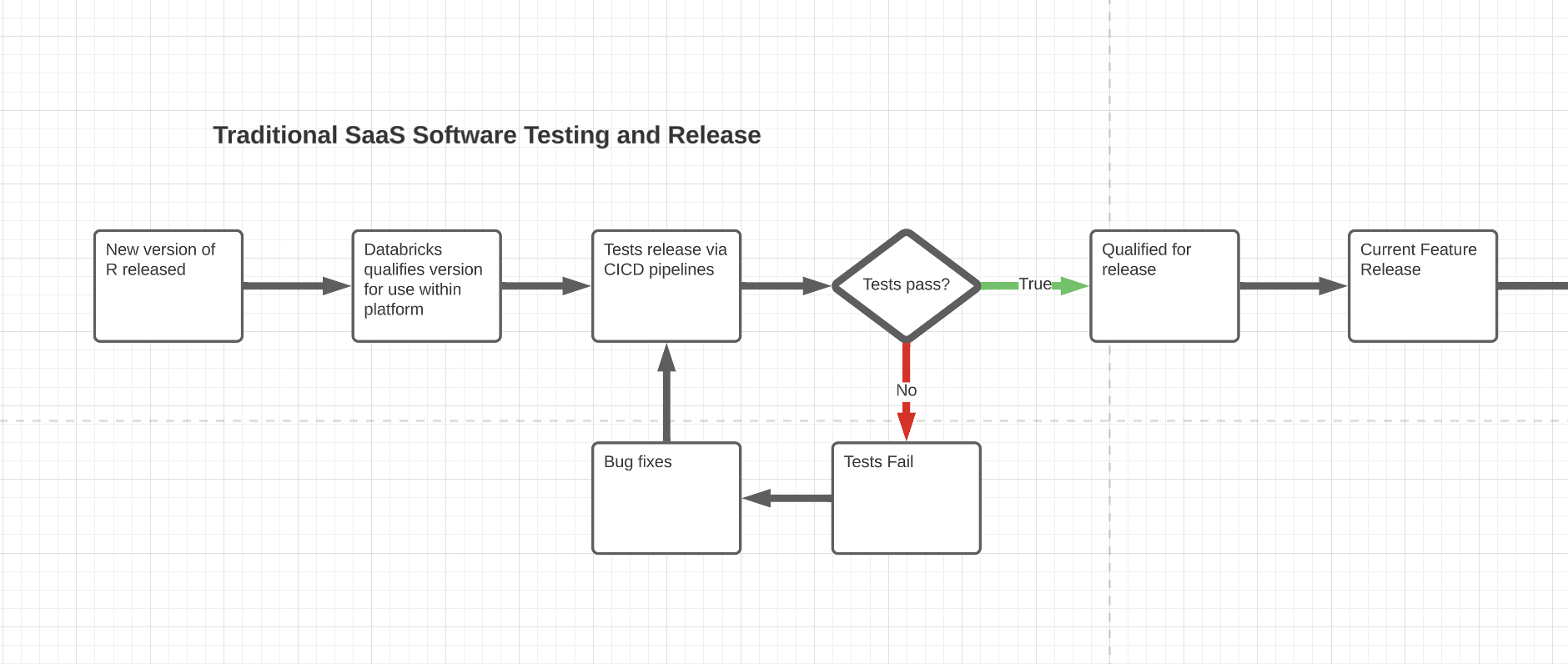
As Databricks makes changes to their process or ecosystem, you can see the SDLC in a simplified view. Databricks automates their delivery and testing so that every user of the package, application, access, or feature has a good experience and is consistent and predictable.
Features are identified, like an updated version of R, and the Databricks development team upgrades the version, tests it and then releases it following an Agile development process. Though they do not state they are qualified or validated using CFR 21 Part 11, Seagen Azure is qualified because Databricks is considered a Platform-as-a-Service represented as a SaaS. It is up to Seagen to validate how they will use the environment.
Data Lakehouse
Currently, several development teams are using Delta Lake and Data Lakehouse. These teams use Delta Lake and Lakehouse to track data lineage and changes by using date/time checkpoints and then seeing the changes through time. These checkpoints are managed by the system and Databricks directly. As the solution evolves, Databricks produces feature sets, deploys those changes and notifies the consumers of that service. This can be controlled by the code that is written.
As we use the Delta Lake or Lakehouse, Seagen decides which packages to use. Though they are available on the platform, the business teams decide when to use them. We have control over the packages and libraries we use.
Use Cases
There are many use cases for the use of Databricks. These are just a few.
Use Case: Bioinformatics uses Databricks to analyze vast amounts of sequenced data
Use Case: Globlal IT uses Databricks to correlate system alerts or audits with the data being produced from the system to find anomalies
Use Case: Biostatistics uses Databricks to create catalogs of data
Use Case: Stastical Programming uses Databricks to replace the legacy R platform
Use Case: Research uses Databricks to process data and create a data hub
Use Case: Data Science uses Databricks to process image data for neural networks and machine learning
Use Case: Global IT uses Databricks to standardize their datasets across multiple domains
Mitigating Risk
There will be times that developers, scientists, engineers or analysts use Databricks in a way that is unintended because the platform is designed for exploration and data wrangling. As such, Global IT and the application teams need to perform extra work to mitigate processes that would normally be handled by the platform provider. Here are some of those issues and how they would be mitigated.
Package application - When packages and libraries are added to Databricks, the application team and/or Global IT will perform a round of testing to ensure that package or library is going to function within the bounds of the Databricks platform. The following testing will be run.
Regression testing
Notebook testing (analytics)
Vulnerability analysis (research using source or site)
Connectivity to Data Lake - When a Databricks platform needs to be connected to data lake, storage, or other Azure service, a Managed Identity is used to bridge the security boundaries. This ensures obfuscation of the tokens necessary to use the services.
Multi-team Utilization - When multiple teams use a single Databricks cluster, isolation is created and user segmentation is designed to eliminate one team gaining access to another team’s information. This is simple using the predefined access controls within Databricks and Azure. As seen in the picture above, security and access controls are created and utilized to ensure proper access.
At the same time, audits, logging, and telemetry is used to ensure there is visibility to the utilization of the service.
Removing Access - Removing access is done through the corporate IAM controls and is automated.
F. 2023 Roadmap
In Q4, 2022, the Cloud Transformation and DevOps team to create centralized workspaces based on need from various teams. For instance, Data Science needs a compute cluster with GPU capabilities as does Bioinformatics and RNA/DNA sequencing. They can use the same workspace and cluster to optimize the ecosystem. That means that we will likely need to expand the Data Science subscriptions to support this. Other teams may request an instance but should share and use RBAC in the delivery pipeline.
Another option is to create domain driven clusters. For instance, if HR needs a cluster, they would have a general purpose cluster. If the ERP team needs a cluster, they would have several teams join them.
Use of Databricks cluster policies (specify the type of instances they can choose from, can have cluster policies based on user group)
Policies are setup in the instance so Seagen should maximize instances
Changes include grouping teams together into instances and then using policies to identify which teams use which clusters
The following programs and teams will use Databricks with Data Lake / Delta Lake enabled in 2023.
R Compute
Launchpad Manufacturing (GMP)
Launchpad Supply Chain (GMP)
Launchpad IT Operations
Bioinformatics
Clinical Data Management
TOPS Data Science (GMP)
Biostatistics
Research Data Hub
Data Mesh Architecture phase 1.0
Data Science Computing
G. 2024 Roadmap
Research
GIT Operations
Data Mesh Architecture phase 2.0
Data Science Computing
H. Known Issues
There are several known issues that can impact Azure Databricks. Here are some of the most common issues to be aware of:
Performance issues: If the cluster is not properly sized, it can impact performance and availability, causing issues with the speed and reliability of Azure Databricks.
Security issues: Security is a critical concern when it comes to Azure Databricks. It is important to ensure that Azure Databricks is secured and that access to the solution is restricted to authorized personnel.
Compatibility issues: Azure Databricks may not be compatible with all platforms, devices, or languages. It is important to ensure that Azure Databricks is compatible with the organization’s existing infrastructure before implementation.
Scalability issues: Scalability issues can arise when scaling up or down the cluster. It is important to ensure that the cluster can scale to meet the needs of the organization.
Data accuracy issues: Data accuracy issues can arise when the data is not processed correctly. It is important to ensure that data is processed accurately to avoid data accuracy issues.
Integration issues: Integration issues can arise when integrating Azure Databricks with other systems and applications. It is important to ensure that Azure Databricks is designed to work seamlessly with other systems and applications to avoid integration issues.
Testing issues: Testing issues can arise when testing Azure Databricks. It is important to ensure that testing is carried out thoroughly and that all aspects of Azure Databricks functionality are tested.
Cost issues: Cost issues can arise if the organization is not properly managing usage and costs. It is important to ensure that usage and costs are managed effectively to avoid cost issues.
Overall, Azure Databricks requires careful planning and management to ensure that it is functioning correctly and meeting the needs of all stakeholders involved in the project. By being aware of these known issues and taking steps to address them, you can improve the quality of Azure Databricks and ensure the success of your project.
I. GxP Validation
Responding to the Vendor Qualification Questionnaire
PRV1.1
Does the business have a Privacy and Personal Data Protection policy?
The vendor responded by stating that their platform is supported by Microsoft. In fact they stated,
Databricks employees are generally not permitted to respond to security questionnaires for Azure Databricks, as the Azure Databricks product is provided by Microsoft and Databricks is only a sub-processor of Microsoft. Most security questionnaire needs are applicable to Azure policies or may involve other components outside of Databricks control. The good news is that most customers who ask us about Azure Databricks questionnaires have already completed a review of all Azure services, and so they’re already approved to use Azure Databricks. If not, Databricks is happy to support the Azure team in completing questionnaires.
PRV 1.2
Does the business have a Chief Privacy/Data Protection Officer who ensures compliance with EU GDPR and other country, local, and Independent Ethics Committee-required privacy and data protection practices?
Seagen has a legal team that reviews the documentation from the vendor in detail and highlights issues with their software. Databricks followed the approved Software Intake process with all appropriate reviews. If something occurs at the Databricks level, GIT expects legal to pursue the vendor and manage the relationship.
1.2 Remediation
In the event this occurs, Seagen will evaluate the risk at that time and take necessary steps to either limit the access of data or identify and trace the lineage of the data in order to know how it is used or processed. That will provide Seagen with the ability to understand impacts should the relationship end.
PRV 2.1
Does the business apply Privacy by Design requirements and have documented procedures for defining personally identifying information, describing what is being collected and the purpose of its collection, and ensuring its confidentiality, protection, and security?
Yes the vendor does provide ample documentation, how-tos, videos, and even sample notebooks that show this information. Identifiable information is 2 pronged.
Seagen employees and 3rd parties user information
Data being consumed and used
In both cases, the documentation explains in detail how to manage access and what information is managed as seen from this guide. Manage Access Control.
2.1 Remediation
In the event of internal or external issues, Seagen works with the Identity Access Management team to resolve said issues or create a step-by-step remediation process.
PRV2.2
Do those practices include documenting the lawful basis (in the EU) for its collection/use, the types of persons to whom it will be released, the countries to which it may be transferred, the rights of individuals with respect to their personal information, and compliance monitoring?
Again, as stated in PRV2.1, GIT trusts the Legal process to have covered these topics.
2.2 Remediation
Same as PRV2.1
PRV3.1
Does the business have a documented process for conducting Privacy Impact Assessments or documentation explaining why they are not applicable to their organization?
Looking at Databricks from this perspective, at any time, Seagen can conduct a Privacy Impact Assessment against the implemented Databricks environment(s). We can also invite Databricks Support to that assessment so they can provide insight into the inner workings of the application or platform.
More information can be found here.
3.1 Remediation
Seagen should perform at least one privacy assessment each year.
PRV4.1
Does the business have documented procedures for enhancing privacy and protecting personal data, both at the time of determining the means for processing data and at the time of the actual processing (e.g., adhering to the data minimization principle, encryption at rest and during transit, de-identification, pseudonymization)?
Databricks offers a robust ecosystem that can use industry leading tools like Unity Catalog, Azure Purview, or other developed process as well as libraries that contain processes that can be applied to the data. They also have a robust product enhancement lifecycle that sees many upgrades throughout the year. The following configurations are standard with the Databricks environment.
Encryption at rest
Encryption in transit
Zero Trust Principles for access
Data controls like Delta Lake for tracking changes to individual fields, schemas or datasets
Unity catalog that tracks data assets across many workspaces
Lineage that shows where data came from and where it is going
4.1 Remediation
The principles of:
de-identification
pseudonymization are processes as well as obfuscation
de-duplication
data cleansing
etc. are the responsibility of Seagen and its data engineers or scientists. The Databricks platform is a data compute layer but the models created by the scientists or engineers will include those things. It is the recommendation of Enterprise Architecture to create processes for each of these items as well as encrypt at rest, in transit.
PRV4.2
Where pseudonymization is deployed, does the business have technical and organizational measures in place to separate pseudonymous data from identification keys?
Databricks support pseudonymization but it is the responsibility of Seagen to activate and configure it. More information can be found in the GDPR and CCPA Compliance with Data Lake document.
4.2 Remediation
Same as PRV4.1 though also implementing Delta Lake pattern to track lineage and manage deletions. See link above.
PRV5.1
Does the business have written procedures for documenting the data flow for the organizations/for individual projects? (The data flow consists of the personal data the business holds, where it came from, and with whom the business shares the data.)
Databricks is designed to be only utilized by Seagen. Because it is deployed to Seagen’s Azure tenant, neither Microsoft nor Databricks have access to the environments, ecosystems, data, personal information, etc. If support is needed, and the support person needs to gain access to the environment, they initiate a screen share and walk the engineer or support person through the process.
5.1 Remediation
What happens if a Databricks environment is deleted and needs to be reinstated?
Azure can reset the Databricks environment by restoring a backup of the ecosystem. This is done by submitting a support ticket through Global IT.
PRV6.1
Does the business have documented procedures (including standards, responsibilities, and documentation requirements) in place to ensure that individuals are informed of all required privacy provisions in Privacy Notice or Privacy Consent, including the individuals' right to confirm if and how their data are being processed, data retention, right for erasure, right to object to (or limit use of) processing their data, right to receive a copy of their personal data and to have it transmitted to other organizations, and the complaint process?
The Databricks environment is a Platform-as-a-Service. As such, it is Seagen’s responsibility to track the items noted in this request. That said the following remediation should be implemented to support the aspects of this item.
6.1 Remediation
The Databricks environments should use Delta Lake on Azure Data Lake to bridge this gap and ensure personally identifiable, personal information regarding an individual is traced and even verify when it is deleted. Delta Lake creates checkpoints that can provide information about data being used throughout the data science or data management process. To do that Seagen can use a workflow like Pipeline Creation. Seagen also uses the Medallion Lakehouse Architecture coupled with the Data Mesh Architecture to ensure pipelines and data flows are prescriptive and well documented based on patterns and standards.
PRV7.1
Does the business have documented procedures for receiving, processing, and responding to Personal Data Subject Requests submitted by Data Subjects per their rights under GDPR, for access, rectification, restriction of processing, erasure, data portability, and/or objections to processing their personal data, and/or for supporting the Client in doing so?
Again, like the previous responses, it is Seagen’s responsibility to ensure we manage data properly to perform these actions. Data can be added, edited, and deleted but is traced using Delta Lake.
7.1 Remediation
Seagen will employ Delta Lake as a strategy as stated above to meet this requirement.
PRV8.1
Does the business have documented procedures for detecting, reporting, and investigating personal data breaches (both in its own operations and at subcontracted vendors), and for communicating confirmed breaches to impacted parties (including Client) within timelines dictated by applicable regulations and agreements?
Databricks security is very robust and as outlined above, follows the Azure security principles but, also has its own security and protocols. On top of that, Seagen also employs Zero Trust Architecture to ensure microsegmentation, limited or no access to core configurations or systems, and the ability to isolate or segment individual services with specific purpose or context.
8.1 Remediation
With the Databricks platform, all of these security in depth strategies and practices makes Databricks a good candidate to secure and use data. However, Seagen needs to follow the Cloud Adoption Framework and the Databricks Security Guide to ensure proper alignment. The risk is very low when done.
PRV9.1
Does the business train all individuals who have access to personal data on the policy and/or practices that ensure confidentiality, protection, and security of personal data? If yes, please describe.
Being that Databricks is a Platform-as-a-Service and has volumes of how-tos, guides, and configuration standards, it is reasonable that Databricks leads the community in confidentiality, protection, and security of personal data. They provide the mechanisms coupled with Azure to ensure this is done. However, Seagen needs to configure their enviornment to use these features appropriately.
9.1 Remediation
How is this done? By following this configuration.
Azure Active Directory connected to manage authentication and authorization
GitHub Enterprise connected to manage code versioning
Geolocation replication to at least one other location at the storage layer
Bi-annual reviews of security audits
Correlation notebook that identifies anomalies at the audit layer
RV10.1
Does the business, where applicable, maintain accreditation from all applicable agencies?
Databricks does have a published Security and Trust Center. From a compliance perspective, they have the following certifications and followed standards.
CCPA
Department of Defense
FedRAMP
GDPR
HIPAA
HITRUST
ISO 27001
ISO 27017
ISO 27018
PCI DSS
AICPA / SOC
10.1 Remediation
Based on the rigor that comes from these standards and certifications, the risk of not being CFR 21 Part 11 compliant is low. This is because that standard requires Seagen document what we are doing, how we are doing it and then testing that we did what we said we would. That is a great oversimplification however, using automation, documentation, Azure qualification of Databricks as a PaaS and qualification of the ancillary services, Global IT feels the impact is relatively low and Seagen is required to perform the tests necessary to use the platform.
[x] Reviewed by Enterprise Architecture
[x] Reviewed by Application Development
[x] Reviewed by Data Architecture